
Problem Statement
Imagine you have multiple transformation running across multiple slave servers. Now if one of the slave server fails, the transformation running on the job fails. The idea is to build your transformation in a framework so that the failing jobs in slave servers are pushed back/executed to the next available slave servers. This is what load balancing of jobs is all about and i will try to explain a framework which i have worked upon in Kettle.
Solution
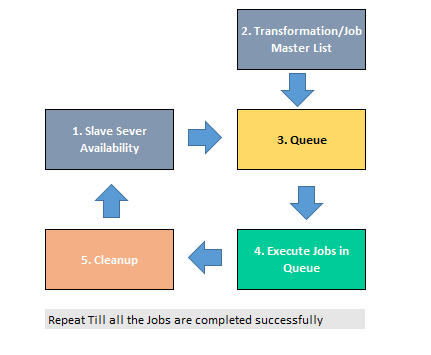
The solution basically lies in carefully designing your ETL solution. This solution can be divided into 5 major parts:
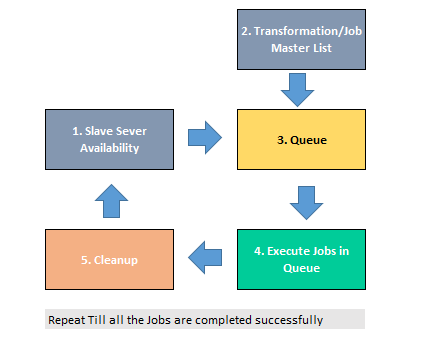
- Slave Server Availability: The idea is to monitor your slave servers and keep a track of all the processes like number of jobs running on a slave, memory usage, etc. If you have 3 transformations running on Slave A, then this job will display the number of jobs running on a slave = 3(three). This job will also do a check based on a *threshold value of the server.
- Transformation/Job Master List: This metadata table will save the details of your jobs/transformation. The idea is to maintain a data dictionary of your Job Name, Job Location, Job status, etc. Upon each successful execution of the job, this metadata dictionary needs to be updated. For every failure in jobs, the same has to be updated. This part of the query keeps track of all the jobs that needs to be executed.
- Queue: The queue is the most important part of this framework. This is the place where all the jobs that are waiting for execution is assigned an available slave server. This includes all the jobs that are in waiting state and error state. The assignment of the slave server to a job is based upon the *threshold value.
- Execute Jobs on Queue: This part of the code executes the jobs on the Slave server based on the queue in Step #3. Now, if a job fails in the slave server, then the status of the job is sent back to Step #2 and #3 where the code is again being queue for execution. (Note: The status of a job, whether its successful or not, is determined by reading the log files. Log files can be either in a database or a file).
- Slave Cleanup: This part is though optional, but if you are using Carte server then you will need to cleanup the status of the jobs from the carte. This is a small bug in Pentaho Kettle which doesn’t properly reflect the status of a job. It means even if a job is completed on the carte, the status of the job on the carte will not be shown as completed. This issue can be ignored since carte is made only to act as a platform but not to physically execute a job on the slaves. So in order to avoid the issue of wrong slave availability in step #1, we need to cleanup the slaves for all the completed Jobs.
[*Threshold: This term is used in this blog as a benchmark for a single slave server. Imagine your slave server (Slave A) is having 4GB of memory. If you are running 2 jobs that uses 3GB of your server memory then the server cannot accommodate another job (assuming it also consumes 2GB of memory). So a threshold value will act as a check for the jobs to be executed.]
Scheduling
This entire framework needs to be scheduled at a certain interval of time. I have executed this job after every 30sec. This is to continuous monitor the slaves and the job across the slave. This part is important as a final cherry on this framework.
A sample image of the job structure looks like below:
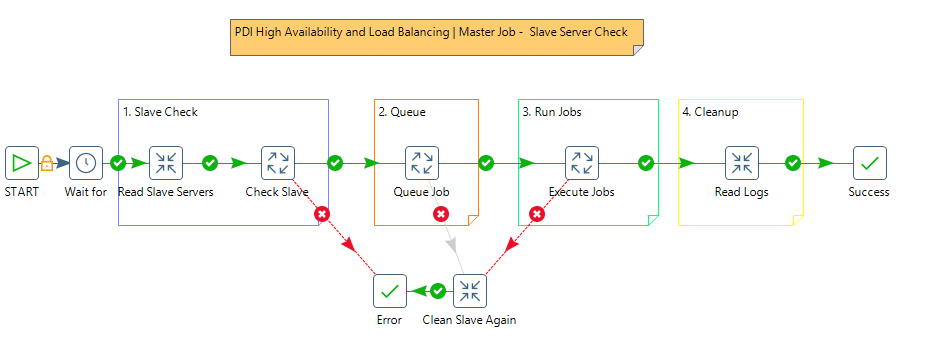
In the above picture Step #2 is merged in the “Queue Job”.
Code

Subscribe to continue reading
Subscribe to get access to the rest of this post and other subscriber-only content.
